Sun, 30 Apr 2017
What do you mean ExceptT doesn't Compose?
Disclaimer: I work at Ambiata (our Github presence) probably the biggest Haskell shop in the southern hemisphere. Although I mention some of Ambiata's coding practices, in this blog post I am speaking for myself and not for Ambiata. However, the way I'm using ExceptT and handling exceptions in this post is something I learned from my colleagues at Ambiata.
At work, I've been spending some time tracking down exceptions in some of our Haskell code that have been bubbling up to the top level an killing a complex multi-threaded program. On Friday I posted a somewhat flippant comment to Google Plus:
Using exceptions for control flow is the root of many evils in software.
Lennart Kolmodin who I remember from my very earliest days of using Haskell in 2008 and who I met for the first time at ICFP in Copenhagen in 2011 responded:
Yet what to do if you want composable code? Currently I have
type Rpc a = ExceptT RpcError IO a
which is terrible
But what do we mean by "composable"? I like the wikipedia definition:
Composability is a system design principle that deals with the inter-relationships of components. A highly composable system provides recombinant components that can be selected and assembled in various combinations to satisfy specific user requirements.
The ensuing discussion, which also included Sean Leather, suggested that these two experienced Haskellers were not aware that with the help of some combinator functions, ExceptT composes very nicely and results in more readable and more reliable code.
At Ambiata, our coding guidelines strongly discourage the use of partial functions. Since the type signature of a function doesn't include information about the exceptions it might throw, the use of exceptions is strongly discouraged. When using library functions that may throw exceptions, we try to catch those exceptions as close as possible to their source and turn them into errors that are explicit in the type signatures of the code we write. Finally, we avoid using String to hold errors. Instead we construct data types to carry error messages and render functions to convert them to Text.
In order to properly demonstrate the ideas, I've written some demo code and made it available in this GitHub repo. It compiles and even runs (providing you give it the required number of command line arguments) and hopefully does a good job demonstrating how the bits fit together.
So lets look at the naive version of a program that doesn't do any exception handling at all.
import Data.ByteString.Char8 (readFile, writeFile)
import Naive.Cat (Cat, parseCat)
import Naive.Db (Result, processWithDb, renderResult, withDatabaseConnection)
import Naive.Dog (Dog, parseDog)
import Prelude hiding (readFile, writeFile)
import System.Environment (getArgs)
import System.Exit (exitFailure)
main :: IO ()
main = do
args <- getArgs
case args of
[inFile1, infile2, outFile] -> processFiles inFile1 infile2 outFile
_ -> putStrLn "Expected three file names." >> exitFailure
readCatFile :: FilePath -> IO Cat
readCatFile fpath = do
putStrLn "Reading Cat file."
parseCat <$> readFile fpath
readDogFile :: FilePath -> IO Dog
readDogFile fpath = do
putStrLn "Reading Dog file."
parseDog <$> readFile fpath
writeResultFile :: FilePath -> Result -> IO ()
writeResultFile fpath result = do
putStrLn "Writing Result file."
writeFile fpath $ renderResult result
processFiles :: FilePath -> FilePath -> FilePath -> IO ()
processFiles infile1 infile2 outfile = do
cat <- readCatFile infile1
dog <- readDogFile infile2
result <- withDatabaseConnection $ \ db ->
processWithDb db cat dog
writeResultFile outfile result
Once built as per the instructions in the repo, it can be run with:
dist/build/improved/improved Naive/Cat.hs Naive/Dog.hs /dev/null Reading Cat file 'Naive/Cat.hs' Reading Dog file 'Naive/Dog.hs'. Writing Result file '/dev/null'.
The above code is pretty naive and there is zero indication of what can and cannot fail or how it can fail. Here's a list of some of the obvious failures that may result in an exception being thrown:
- Either of the two readFile calls.
- The writeFile call.
- The parsing functions parseCat and parseDog.
- Opening the database connection.
- The database connection could terminate during the processing stage.
So lets see how the use of the standard Either type, ExceptT from the transformers package and combinators from Gabriel Gonzales' errors package can improve things.
Firstly the types of parseCat and parseDog were ridiculous. Parsers can fail with parse errors, so these should both return an Either type. Just about everything else should be in the ExceptT e IO monad. Lets see what that looks like:
{-# LANGUAGE OverloadedStrings #-}
import Control.Exception (SomeException)
import Control.Monad.IO.Class (liftIO)
import Control.Error (ExceptT, fmapL, fmapLT, handleExceptT
, hoistEither, runExceptT)
import Data.ByteString.Char8 (readFile, writeFile)
import Data.Monoid ((<>))
import Data.Text (Text)
import qualified Data.Text as T
import qualified Data.Text.IO as T
import Improved.Cat (Cat, CatParseError, parseCat, renderCatParseError)
import Improved.Db (DbError, Result, processWithDb, renderDbError
, renderResult, withDatabaseConnection)
import Improved.Dog (Dog, DogParseError, parseDog, renderDogParseError)
import Prelude hiding (readFile, writeFile)
import System.Environment (getArgs)
import System.Exit (exitFailure)
data ProcessError
= ECat CatParseError
| EDog DogParseError
| EReadFile FilePath Text
| EWriteFile FilePath Text
| EDb DbError
main :: IO ()
main = do
args <- getArgs
case args of
[inFile1, infile2, outFile] ->
report =<< runExceptT (processFiles inFile1 infile2 outFile)
_ -> do
putStrLn "Expected three file names, the first two are input, the last output."
exitFailure
report :: Either ProcessError () -> IO ()
report (Right _) = pure ()
report (Left e) = T.putStrLn $ renderProcessError e
renderProcessError :: ProcessError -> Text
renderProcessError pe =
case pe of
ECat ec -> renderCatParseError ec
EDog ed -> renderDogParseError ed
EReadFile fpath msg -> "Error reading '" <> T.pack fpath <> "' : " <> msg
EWriteFile fpath msg -> "Error writing '" <> T.pack fpath <> "' : " <> msg
EDb dbe -> renderDbError dbe
readCatFile :: FilePath -> ExceptT ProcessError IO Cat
readCatFile fpath = do
liftIO $ putStrLn "Reading Cat file."
bs <- handleExceptT handler $ readFile fpath
hoistEither . fmapL ECat $ parseCat bs
where
handler :: SomeException -> ProcessError
handler e = EReadFile fpath (T.pack $ show e)
readDogFile :: FilePath -> ExceptT ProcessError IO Dog
readDogFile fpath = do
liftIO $ putStrLn "Reading Dog file."
bs <- handleExceptT handler $ readFile fpath
hoistEither . fmapL EDog $ parseDog bs
where
handler :: SomeException -> ProcessError
handler e = EReadFile fpath (T.pack $ show e)
writeResultFile :: FilePath -> Result -> ExceptT ProcessError IO ()
writeResultFile fpath result = do
liftIO $ putStrLn "Writing Result file."
handleExceptT handler . writeFile fpath $ renderResult result
where
handler :: SomeException -> ProcessError
handler e = EWriteFile fpath (T.pack $ show e)
processFiles :: FilePath -> FilePath -> FilePath -> ExceptT ProcessError IO ()
processFiles infile1 infile2 outfile = do
cat <- readCatFile infile1
dog <- readDogFile infile2
result <- fmapLT EDb . withDatabaseConnection $ \ db ->
processWithDb db cat dog
writeResultFile outfile result
The first thing to notice is that changes to the structure of the main processing function processFiles are minor but all errors are now handled explicitly. In addition, all possible exceptions are caught as close as possible to the source and turned into errors that are explicit in the function return types. Sceptical? Try replacing one of the readFile calls with an error call or a throw and see it get caught and turned into an error as specified by the type of the function.
We also see that despite having many different error types (which happens when code is split up into many packages and modules), a constructor for an error type higher in the stack can encapsulate error types lower in the stack. For example, this value of type ProcessError:
EDb (DbError3 ResultError1)
contains a DbError which in turn contains a ResultError. Nesting error types like this aids composition, as does the separation of error rendering (turning an error data type into text to be printed) from printing.
We also see that with the use of combinators like fmapLT, and the nested error types of the previous paragraph, means that ExceptT monad transformers do compose.
Using ExceptT with the combinators from the errors package to catch exceptions as close as possible to their source and converting them to errors has numerous benefits including:
- Errors are explicit in the types of the functions, making the code easier to reason about.
- Its easier to provide better error messages and more context than what is normally provided by the Show instance of most exceptions.
- The programmer spends less time chasing the source of exceptions in large complex code bases.
- More robust code, because the programmer is forced to think about and write code to handle errors instead of error handling being and optional afterthought.
Want to discuss this? Try reddit.
Posted at: 12:22 | Category: CodeHacking/Haskell | Permalink
Sat, 18 Oct 2014
Haskell : A neat trick for GHCi
Just found a really nice little hack that makes working in the GHC interactive REPL a little easier and more convenient. First of all, I added the following line to my ~/.ghci file.
:set -DGHC_INTERACTIVE
All that line does is define a GHC_INTERACTIVE pre-processor symbol.
Then in a file that I want to load into the REPL, I need to add this to the top of the file:
{-# LANGUAGE CPP #-}
and then in the file I can do things like:
#ifdef GHC_INTERACTIVE import Data.Aeson.Encode.Pretty prettyPrint :: Value -> IO () prettyPrint = LBS.putStrLn . encodePretty #endif
In this particular case, I'm working with some relatively large chunks of JSON and its useful to be able to pretty print them when I'm the REPL, but I have no need for that function when I compile that module into my project.
Posted at: 09:16 | Category: CodeHacking/Haskell | Permalink
Wed, 11 Jun 2014
Moving from Wai 2.X to 3.0.
Michael Snoyman has just released version 3.0 of Wai, the Haskell Web Application Interface library which is used with the Yesod Web Framework and anything that uses the Warp web server. The important changes for Wai are listed this blog post. The tl;dr is that removing the Conduit library dependency makes the Wai interface more easily usable with one of the alternative Haskell streaming libraries, like Pipes, Stream-IO, Iterator etc.
As a result of the above changes, the type of a web application changes as follows:
-- Wai > 2.0 && Wai < 3.0 type Application = Request -> IO Response -- Wai == 3.0 type Application = Request -> (Response -> IO ResponseReceived) -> IO ResponseReceived
Typically a function of type Application will be run by the Warp web server using one of Warp.run or associated functions which have type signatures of:
run :: Port -> Application -> IO () runSettings :: Settings -> Application -> IO () runSettingsSocket :: Settings -> Socket -> Application -> IO ()Source runSettingsConnection :: Settings -> IO (Connection, SockAddr) -> Application -> IO ()
Its important to note that the only thing that has changed about these Warp functions is the Application type. That means that if we have a function oldWaiApplication that we want to interface to the new version of Wai, we can just wrap it with the following function:
newWaiApplication :: Manager -> Request -> (Response -> IO ResponseReceived) -> IO ResponseReceived newWaiApplication mgr wreq receiver = oldWaiApplication mgr wreq >>= receiver
and use newWaiApplication in place of oldWaiApplication in the call to whichever of the Warp run functions you are using.
Posted at: 20:16 | Category: CodeHacking/Haskell | Permalink
Wed, 08 Jan 2014
When QuickCheck Fails Me
This is an old trick I picked up from a colleague over a decade ago and have re-invented or re-remembered a number of times since.
When implementing complicated performance critical algorithms and things don't work immediately, the best idea is to drop back to the old formula of:
- Make it compile.
- Make it correct.
- Make it fast.
Often than means implementing slow naive versions of parts of the algorithm first and then one-by-one replacing the slow versions with fast versions. For a given function of two inputs, this might give me two functions with the identical type signatures:
functionSlow :: A -> B -> C functionFast :: A -> B -> C
that can be used interchangeably.
When it comes to implementing the fast versions, the slow versions can be used to check the correct-ness of the fast version using a simple QuickCheck property like:
\ a b -> functionFast a b == functionSlow a b
This property basically just asks QuickCheck to generate a, b pairs, pass these to both functions and compare their outputs.
With something like this, QuickCheck usually all finds the corner cases really quickly. Except for when it doesn't. QuickCheck uses a random number generator to generate inputs to the function under test. If for instance you have a function that takes a floating point number and only behaves incorrectly when that input is say exactly 10.3, the chances of QuickCheck generating exactly 10.3 and hitting the bug are very small.
For exactly this reason, using the technique above sometimes doesn't work. Sometimes the fast version has a bug that Quickcheck wasn't able to find.
When this happens the trick is to write a third function:
functionChecked :: A -> B -> C
functionChecked a b =
let fast = functionFast a b
slow = functionSlow a b
in if fast == slow
then fast
else error $ "functionFast " ++ show a ++ " " ++ show b
++ "\nreturns " ++ show fast
++ "\n should be " ++ show slow
which calculates the function output using both the slow and the fast versions, compares the outputs and fails with an error if the two function outputs are not identical.
Using this in my algorithm I can then collect failing test cases that QuickCheck couldn't find. With a failing test case, its usually pretty easy to fix the broken fast version of the function.
Posted at: 21:03 | Category: CodeHacking/Haskell | Permalink
Sun, 29 Dec 2013
Haskell : The Problem with Integer.
Haskellers may or not be aware that there are two libraries in the GHC sources for implementing the Integer data type.
The first, integer-gmp links to the GNU Multiple Precision Arithmetic Library which is licensed under the GNU LGPL. On most systems, libgmp is dynamically linked and all is fine. However, if you want to create statically linked binaries from Haskell source code you end up with your executable statically linking libgmp which means your binary needs to be under an LGPL compatible license if you want to release it. This is especially a problem on iOS which doesn't allow dynamic linking anyway.
The second Integer implementation is integer-simple which is implemented purely in Haskell (using a number of GHC extension) and is BSD licensed.
So why doesn't everyone just the the BSD licensed one? Well, integer-simple has a reputation for being slow. Even more intriguingly, I seem to remember Duncan Coutts telling me a couple of years ago that integer-simple was a little faster than integer-gmp when the Integer was small enough to fit in a single machine Word, but much slower when that was not the case. At the time I heard this, I decided to look into it at some time. That time has come.
A couple of weeks ago I put together some scripts and code to allow me to compile the two Integer implementations into a single program and benchmark them against each other. My initial results looked like this:
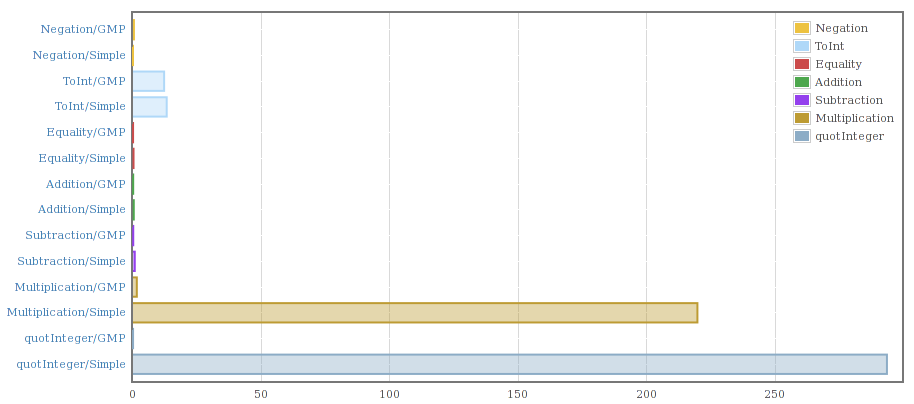
That confirmed the slowness for multiplication and division if nothing else.
Taking a look at the code to integer-simple I found that it was storing Word#s (unboxed machine sized words) in a Haskell list. As convenient as lists are they are not an optimal data structure for a something like the Integer library.
I have already started work on replacement for both versions of the current Integer library with the following properties:
- BSD licensed.
- Implemented in Haskell (with GHC extensions) so there are no issues with linking to external C libraries.
- Fast. I'm aiming to outperform both integer-simple and integer-gmp on as many benchmarks as possible.
- Few dependencies so it can easily replace the existing versions. Currently my code only depends on ghc-prim and primitive.
So far the results are looking encouraging. For Integer values smaller than a machine word, addition with my prototype code is faster than both existing libraries and for adding large integers its currently half the speed of integer-gmp, but I have an idea which will likely make the new library match the speed of integer-gmp.
Posted at: 10:08 | Category: CodeHacking/Haskell | Permalink
Tue, 22 Jan 2013
parMap to the Rescue.
I had a long running, CPU intensive Haskell program that I wanted to speed up. The program was basically a loop consisting of a a small sequential part followed by a map of a CPU intensive pure function over a list of 1500 elements.
Obviously I needed some sort of parallel map function and I had a faint recollection of a function called parMap. The wonderful Hoogle search engine pointed me to the parMap documentation.
Changing the existing sequential map operation into a parallel map required a 3 line change (one of them to import the required module). I then added "-threaded" to the compile command line to enable the threaded runtime system in the generated executable and "+RTS -N6" to the executable's command line. The resulting program went from using 100% of 1 CPU to using 560% of 1 CPU on an 8 CPU box. Win!
I wish all code was this easy to parallelize.
Posted at: 22:08 | Category: CodeHacking/Haskell | Permalink
Sat, 22 Dec 2012
My Space is Leaking.
Over the last couple of days I wrote a small Haskell program to read a large CSV file (75Meg, approx. 1000 columns and 50000 rows) and calculate some statistics. Since I would have to do this for much larger files as well, I decided to use the csv-conduit library to read the data and use a function passed to Data.Conduit's sinkState to calculate the statistics.
The code was pretty easy to put together, and only came to about 100 lines of code. Unfortunately, when I ran the program, it tried to consume all 8Gig of memory on my laptop and when I actually let it run to completion, it took over an hour to produce useful output.
A bit of quick profiling showed that the problem was with the state used to hold the statistics. The state itself wasn't huge, but Haskell's lazy evaluation meant there were a huge number of thunks (pending calculations) piling up.
Aside : Haskell does lazy (more correctly called non-strict) evaluation by default. This means that values are calculated when they are needed rather than when the program hits that point in the code. For instance if a value is generated by calling a pure function, the GHC runtime will forgo actually calling the function and replace the value with a thunk containing the function and it's input parameters. Later, when the value is actually needed, the runtime will call the function stored in the thunk.
My first attempt to fix this problem was to add some strictness annotations to my data types, but that didn't seem to help. I then looked at the deepseq package and tried adding the $!! operator in a few places. This resulted in a compile error complaining about my data structures not having an NFData instance. A bit of googling for "custom NFData instance" showed up the deepseq-th package which uses Template Haskell to generate NFData instances.
Aside : For a value to be an instance of the NFData typeclass means that it can be fully evaluated, ie a thunk to calculate a value of this type can be forced by deepseq to replace the thunk with the value.
About 10 minutes later I had my code working again, but now it processed the same file in a little over 2 minutes and used less than 0.1% of the 8Gig it was using previously.
I was happy with this. So happy that I decided to thank the author of deepseq-th, Herbert Valerio Riedel (hvr) on the #haskell IRC channel. Herbert was pleased to hear of my success, but suggested that instead of deepseq-th I try using deepseq-generics. Someone else on the channel suggested that this might be slower, but Herbert said that he had not found that to be the case. Switching from one to the other was trivially easy and pleasingly enough the generics version ran just as fast.
That's when José Pedro Magalhães (dreixel in #haskell) said that he had a draft paper "Optimisation of Generic Programs through Inlining" explaining how and why this generic implementation is just as fast as the Template Haskell version. Basically it boils down to the compiler having all the information it needs at compile time to inline and specialize the code to be just as fast as hand written code.
Reflections:
- Streaming I/O libraries like Data.Conduit (there's more than one) do give guarantees about space usage so that when you get a space leak the I/O is probably not the first place to look.
- For small programs its relatively easy to reason about where the space leak is happening.
- For a relatively experienced Haskeller, following the bread crumbs to a working solution is relatively easy.
- Code that uses a struct to accumulate state is a common contributor to space leaks.
- Interacting with the Haskell community can often get a better result than the first thing you find (eg deepseq-generics instead of deepseq-th).
- Generics can be just as fast as Template Haskell generated code.
Posted at: 16:42 | Category: CodeHacking/Haskell | Permalink
Tue, 24 Jan 2012
Benchmarking and QuickChecking readInt.
I'm currently working on converting my http-proxy library from using the Data.Enumerator package to Data.Conduit (explanation of why in my last blog post).
During this conversion, I have been studying the sources of the Warp web server because my http-proxy was originally derived from the Enumerator version of Warp. While digging through the Warp code I found the following code (and comment) which is used to parse the number provided in the Content-Length field of a HTTP header:
-- Note: This function produces garbage on invalid input. But serving an -- invalid content-length is a bad idea, mkay? readInt :: S.ByteString -> Integer readInt = S.foldl' (\x w -> x * 10 + fromIntegral w - 48) 0
The comment clearly states that that this function can produce garbage, specifically if the string contains anything other than ASCII digits. The comment is also correct that an invalid Content-Length is a bad idea. However, on seeing the above code, and remembering something I had seen recently in the standard library, I naively sent the Yesod project a patch replacing the above code with a version that uses the readDec function from the Numeric module:
import Data.ByteString (ByteString)
import qualified Data.ByteString.Char8 as B
import qualified Numeric as N
readInt :: ByteString -> Integer
readInt s =
case N.readDec (B.unpack s) of
[] -> 0
(x, _):_ -> x
About 3-4 hours after I submitted the patch I got an email from Michael Snoyman saying that parsing the Content-Length field is a hot spot for the performance of Warp and that I should benchmark it against the code I'm replacing to make sure there is no unacceptable performance penalty.
That's when I decided it was time to check out Bryan O'Sullivan's Criterion bench-marking library. A quick read of the docs and bit of messing around and I was able to prove to myself that using readDec was indeed much slower than the code I wanted to replace.
The initial disappointment of finding that a more correct implementation was significantly slower than the less correct version quickly turned to joy as I experimented with a couple of other implementations and eventually settled on this:
import Data.ByteString (ByteString)
import qualified Data.ByteString.Char8 as B
import qualified Data.Char as C
readIntTC :: Integral a => ByteString -> a
readIntTC bs = fromIntegral
$ B.foldl' (\i c -> i * 10 + C.digitToInt c) 0
$ B.takeWhile C.isDigit bs
By using the Integral type class, this function converts the given ByteString to any integer type (ie any type belonging to the Integral type class). When used, this function will be specialized by the Haskell compiler at the call site to to produce code to read string values into Ints, Int64s or anything else that is a member of the Integral type class.
For a final sanity check I decided to use QuickCheck to make sure that the various versions of the generic function were correct for values of the type they returned. To do that I wrote a very simple QuickCheck property as follows:
prop_read_show_idempotent :: Integral a => (ByteString -> a) -> a -> Bool
prop_read_show_idempotent freader x =
let posx = abs x
in posx == freader (B.pack $ show posx)
This QuickCheck property takes the function under test freader and QuickCheck will then provide it values of the correct type. Since the function under test is designed to read Content-Length values which are always positive, we only test using the absolute value of the value randomly generated by QuickCheck.
The complete test program can be found on Github in this Gist and can be compiled and run as:
ghc -Wall -O3 --make readInt.hs -o readInt && ./readInt
When run, the output of the program looks like this:
Quickcheck tests.
+++ OK, passed 100 tests.
+++ OK, passed 100 tests.
+++ OK, passed 100 tests.
Criterion tests.
warming up
estimating clock resolution...
mean is 3.109095 us (320001 iterations)
found 27331 outliers among 319999 samples (8.5%)
4477 (1.4%) low severe
22854 (7.1%) high severe
estimating cost of a clock call...
mean is 719.4627 ns (22 iterations)
benchmarking readIntOrig
mean: 4.653041 us, lb 4.645949 us, ub 4.663823 us, ci 0.950
std dev: 43.94805 ns, lb 31.52653 ns, ub 73.82125 ns, ci 0.950
benchmarking readDec
mean: 13.12692 us, lb 13.10881 us, ub 13.14411 us, ci 0.950
std dev: 90.63362 ns, lb 77.52619 ns, ub 112.4304 ns, ci 0.950
benchmarking readRaw
mean: 591.8697 ns, lb 590.9466 ns, ub 594.1634 ns, ci 0.950
std dev: 6.995869 ns, lb 3.557109 ns, ub 14.54708 ns, ci 0.950
benchmarking readInt
mean: 388.3835 ns, lb 387.9500 ns, ub 388.8342 ns, ci 0.950
std dev: 2.261711 ns, lb 2.003214 ns, ub 2.585137 ns, ci 0.950
benchmarking readInt64
mean: 389.4380 ns, lb 388.9864 ns, ub 389.9312 ns, ci 0.950
std dev: 2.399116 ns, lb 2.090363 ns, ub 2.865227 ns, ci 0.950
benchmarking readInteger
mean: 389.3450 ns, lb 388.8463 ns, ub 389.8626 ns, ci 0.950
std dev: 2.599062 ns, lb 2.302428 ns, ub 2.963600 ns, ci 0.950
At the top of the output is proof that all three specializations of the generic function readIntTC satisfy the QuickCheck property. From the Criterion output its pretty obvious that the Numeric.readDec version is about 3 times slower that the original function. More importantly, all three version of this generic function are an order of magnitude faster than the original.
That's a win! I will be submitting my new function for inclusion in Warp.
Update : 14:13
At around the same time I submitted my latest version for readInt Vincent Hanquez posted a comment on the Github issue suggesting I look at the GHC MagicHash extension and pointed me to an example.
Sure enough, using the MagicHash technique resulted in something significantly faster again.
Update #2 : 2012-01-29 19:46
In version 0.3.0 and later of the bytestring-lexing package there is a function readDecimal that is even faster than the MagiHash version.
Posted at: 11:52 | Category: CodeHacking/Haskell | Permalink
Sat, 14 Jan 2012
A Simple Telnet Client Using Data.Conduit.
Below is a simple telnet client written using Haskell's new Conduit library. This library was written by Michael Snoyman the man behind the Yesod Web Framework for Haskell.
The Conduit library is a second generation approach to the problem of guaranteeing bounded memory usage in the presence of lazy evaluation. The first generation of these ideas were libraries like Iteratee, Enumerator, and IterIO. All of these first generation libraries use the the term enumerator for data producers and iteratee for data consumers. The new Conduit library calls data producers "sources" and data consumers "sinks" to make them a little more approachable.
The other big difference between Conduit and the early libraries in this space is to do with guaranteeing early clean up of potentially scarce resources like sockets. Although I have not looked in any detail at the IterIO library, both Iteratee and Enumerator simply rely on Haskell's garbage collector to clean up resources when they are no longer required. The Conduit library on the other hand uses Resource transformers to guarantee release of these resources as soon as possible.
The client looks like this (latest available here):
import Control.Concurrent (forkIO, killThread)
import Control.Monad.IO.Class (MonadIO, liftIO)
import Control.Monad.Trans.Resource
import Data.Conduit
import Data.Conduit.Binary
import Network (connectTo, PortID (..))
import System.Environment (getArgs, getProgName)
import System.IO
main :: IO ()
main = do
args <- getArgs
case args of
[host, port] -> telnet host (read port :: Int)
_ -> usageExit
where
usageExit = do
name <- getProgName
putStrLn $ "Usage : " ++ name ++ " host port"
telnet :: String -> Int -> IO ()
telnet host port = runResourceT $ do
(releaseSock, hsock) <- with (connectTo host $ PortNumber $ fromIntegral port) hClose
liftIO $ mapM_ (`hSetBuffering` LineBuffering) [ stdin, stdout, hsock ]
(releaseThread, _) <- with (
forkIO $ runResourceT $ sourceHandle stdin $$ sinkHandle hsock
) killThread
sourceHandle hsock $$ sinkHandle stdout
release releaseThread
release releaseSock
There are basically three blocks, a bunch of imports at the top, the program's entry point main and the telnet function.
The telnet function is pretty simple. Most of the function runs inside a runResourceT resource transformer. The purpose of these resources transformers is to keep track of resources such as sockets, file handles, thread ids etc and make sure they get released in a timely manner. For example, in the telnet function, the connectTo function call opens a connection to the specified host and port number and returns a socket. By wrapping the connectTo in the call to with then the socket is registered with the resource transformer. The with function has the following prototype:
with :: Resource m
=> Base m a -- Base monad for the current monad stack
-> (a -> Base m ()) -- Resource de-allocation function
-> ResourceT m (ReleaseKey, a)
When the resource is registered, the user must also supply a function that will destroy and release the resource. The with function returns a ReleaseKey for the resource and the resource itself. Formulating the with function this way makes it hard to misuse.
The other thing of interest is that because a telnet client needs to send data in both directions, the server-to-client communication path and the client-to-server communication run in separate GHC runtime threads. The thread is spawned using forkIO and even though the thread identifier is thrown away, the resource transformer still records it and will later call killThread to clean up the thread.
The main core of the program are the two lines containing calls to sourceHandle and sinkHandle. The first of these lines pulls data from stdin and pushes it to the socket hsock while the second pulls from the socket and pushes it to stdout.
It should be noted that the final two calls to release are not strictly necessary since the resource transformer will clean up these resources automatically.
The experience of writing this telnet client suggests that the Conduit library is certainly easier to use than the Enumerator or Iteratee libraries.
Posted at: 13:22 | Category: CodeHacking/Haskell | Permalink
Wed, 31 Dec 2008
Parsec and Expression Parsing.
Haskell's Parsec parsing library (distributed with the GHC compiler since at least version 6.8.2) contains a very powerful expression parsing module Text.ParserCombinators.Parsec.Expr. This module makes it easy to correctly parse arithmetic expressions like the following according to the usual programming language precedence rules.
2 + a * 4 - b
Once parsed, the abstract syntax tree for that expression should look like this:
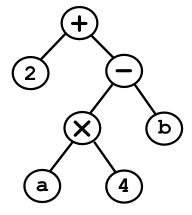
The original Parsec paper by Daan Leijen even gives a small example of using the expression parser. As can be seen below, the operators are defined in a table (ie a list of lists) where the outer list is a set precedence levels (from highest precedence to lowest) and each inner list specifies all the operators for that precedence level.
module Parser
where
import Text.ParserCombinators.Parsec
import Text.ParserCombinators.Parsec.Expr
expr :: Parser Integer
expr = buildExpressionParser table factor <?> "expression"
table :: [[ Operator Char st Integer ]]
table = [
[ op "*" (*) AssocLeft, op "/" div AssocLeft ],
[ op "+" (+) AssocLeft, op "-" (-) AssocLeft ]
]
where
op s f assoc = Infix (do { string s ; return f }) assoc
factor = do { char '(' ; x <- expr ; char ')' ; return x }
<|> number
<?> "simple expression"
number :: Parser Integer
number = do { ds <- many1 digit; return (read ds) } <?> "number"
The above simple example works fine but there is a potential for a rather subtle problem if the expression parser is used in conjunction with the Text.ParserCombinators.Parsec.Token module.
The problem arises when trying to parse expressions in C-like languages which have bitwise OR (|) as well as logical OR (||) and where the bitwise operation has higher precedence than the logical. The symptom was that code containing the logical OR would fail because the expression parser was finding two bitwise ORs. After banging my head against this problem for a considerable time, I posted a problem description with a request for clues to the Haskell Cafe mailing list with the following code snippet:
import qualified Text.ParserCombinators.Parsec.Expr as E
opTable :: [[ E.Operator Char st Expression ]]
opTable = [
-- Operators listed from highest precedence to lowest precedence.
{- snip, snip -}
[ binaryOp "&" BinOpBinAnd E.AssocLeft ],
[ binaryOp "^" BinOpBinXor E.AssocLeft ],
[ binaryOp "|" BinOpBinOr E.AssocLeft ],
[ binaryOp "&&" BinOpLogAnd E.AssocLeft ],
[ binaryOp "||" BinOpLogOr E.AssocLeft ]
]
binaryOp :: String -> (SourcePos -> a -> a -> a)
-> E.Assoc -> E.Operator Char st a
binaryOp name con assoc =
E.Infix (reservedOp name >>
getPosition >>=
return . con) assoc
Unfortunately, no real answer was forthcoming and while I still held out hope that an answer might eventuate, I continued to work on the problem.
Eventually, after reasoning about the problem and looking at the source code to the Token module I realised that the problem was with the behaviour of the reservedOp combinator. This combinator was simply matching the given string at the first precedence level it found so that even if the code contained a logical OR (||) the higher precedence bitwise OR would match leaving the second vertical bar character un-parsed.
My first attempt at a solution to this problem was to define my own combinator reservedOpNf using Parsec's notFollowedBy combinator and use that in place of the problematic reservedOp.
opChar :: String opChar = "+-/%*=!<>|&^~" reservedOpNf :: String -> CharParser st () reservedOpNf name = try (reservedOp name >> notFollowedBy (oneOf opChar))
This solved the immediate problem of distinguishing between bitwise and logical OR, but I soon ran into another problem parsing expressions like this:
if (whatever == -1)
.....
which were failing at the unary minus.
A bit of experimenting suggested that again, the problem was with the behaviour of the reservedOp combinator. In this case it seemed the combinator was matching the given string, consuming any trailing whitespace and then the notFollowedBy was failing on the unary minus.
Once the problem was understood, the solution was easy, replace the reservedOp combinator with the string combinator (which matches the string exactly and doesn't consume trailing whitespace), followed by the notFollowedBy and then finally use the whiteSpace combinator to chew up trailing white space.
reservedOpNf :: String -> CharParser st ()
reservedOpNf name =
try (string name >> notFollowedBy (oneOf opChar) >> whiteSpace)
Despite minor problems like the one above, I am still incredibly impressed with the ease of use and power of Parsec. Over the years I have written numerous parsers, in multiple host languages, using a number of parser generators and I have never before used anything that comes close to matching Haskell and Parsec.
Posted at: 07:28 | Category: CodeHacking/Haskell | Permalink
Mon, 29 Dec 2008
learnHaskell :: Problem -> IO Solution
Over the last week or so I've been learning Haskell. Unlike a previous attempt to learn Erlang I think this one will actually end up bearing fruit. The main thing that slowed down my attempt to learning Erlang was that I didn't have a task to apply it to that exploited the strengths of the language.
For Haskell I have a task that is ideally suited to the language and plays to its strengths; writing a parser for an Javascript-like language. Just like when I learned Ocaml I am jumping in at the deep end with a difficult problem and learning the language on the way (ie as a side-effect of tackling the task itself).
Normally my tool of choice for this task would be Ocaml and I did in fact start out writing a parser in Ocaml using the Menhir parser generator. Menhir creates a parser from an LR(1) grammar specification where the LR(1) means that the grammar is left recursive and must need no more than one token look-ahead to resolve ambiguities. Over two days of intense hacking I made quite a lot of progress on the grammar and then hit a wall; numerous rather incomprehensible shift/reduce and reduce/reduce warnings plus a part of the grammar (raw XML embedded directly into the source code) which was not context free and for which I could not see any possible way of parsing with only one token look-ahead.
Since I already knew Ocaml, I looked around at some of the other parser generators for Ocaml like Aurochs and PCL. Aurochs uses Parsing Expression Grammar (or Packrat parsing) and seemed interesting, but was rejected because it seemed to gave very little control over the Abstract Syntax Tree it generated. PCL on the other hand was a monadic parser combinator library which is basically a port of Haskell's Parsec library to Ocaml. The main problem I saw with PCL was that it used Monads and lazy evaluation, neither of which are very common in standard Ocaml code. PCL was also rather new and I wasn't sure if it was stable and mature enough for quite an advanced parsing task.
Of course I had been hearing good things about Haskell's Parsec library for a couple of years and decided that this was a good time to give it a try. The interesting thing about Parsec is that it uses lazy evaluation to provide what is effectively infinite token look-ahead. Obviously, a Parsec grammar should be written so that it only uses more than one look-ahead when that is absolutely necessary.
With a bit of googling I found a bunch of examples using Parsec for simple things and that was enough code to get me started. A week later, after an IRC question answered by Don Stewart, a bit of help from Conrad Parker and a question answered on the Haskell Cafe mailing list, I am almost as far along as I got with the Ocaml version of the parser.
My impressions of Haskell and Parsec so far are as follows:
- Initially I disliked Haskell's syntax even more than I disliked that of Ocaml, but I am coming to terms with it. I'm even quite liking it.
- The error messages from the Haskell compiler are very much more wordy than those from the Ocaml compiler but not a whole lot more enlightening.
- You don't really need to be comfortable with monads to start cutting Haskell code.
- The two unusual language features of Haskell, monads and lazy evaluation make things like Parsec possible. Without both of these features, Parsec would not be possible.
- Hoogle, the Haskell API search engine is a fantastic resource.
- Parsec is fantastic to use, amazingly powerful and very complete (whenever I find myself writing too much code its usually because there is a already a combinator to do what I need).
- Writing the parser in the language itself (ie Haskell) is so much nicer than writing it in a separate Domain Specific Language like one does with yacc / bison / ocamlyacc / menhir etc.
- Parsec error and warning messages are much easier to understand and debug than the typical shift/reduce and reduce/reduce messages from yacc style parser generators (Menhir has a conflicts output file which helps a little).
- When the parser finds an error in the input its parsing, its much easier to generate good error messages than it is with yacc style parsers.
All in all, I'm really enjoying my foray into the world of Haskell.
Posted at: 09:53 | Category: CodeHacking/Haskell | Permalink

![[operator<< is not my friend]](http://yosefk.com/c++fqa/images/operator.png)
